Todo desenvolvedor sênior já sentiu a frustração de ver um assistente de IA sofrer de “degradação de atenção” após uma sessão intensa de depuração. Esse fenômeno, que chamamos de “teto de vidro” da memória da IA, ocorre porque a janela de contexto atua como uma memória de curto prazo volátil. Quando essa janela satura, o modelo inicia uma compactação agressiva, resultando em deriva de contexto (context drift), onde a IA descarta regras de arquitetura e o estado atual da tarefa para tentar “respirar”.
Para romper esse limite, o Context-Mode surge como uma solução de virtualização de contexto. Operando através do Model Context Protocol (MCP), ele atua como uma ponte arquitetural que separa os dados brutos da percepção direta do modelo, permitindo que a IA mantenha a coesão sem ser soterrada pelo volume de dados. Além disso, reduz significamente o consumo de tokens, o que é um desafio a todo desenvolvedor que trabalha com agent coders: economizar tokens para durar mais.
Relato de Experiência: Auditoria de Eficiência no Claude Code
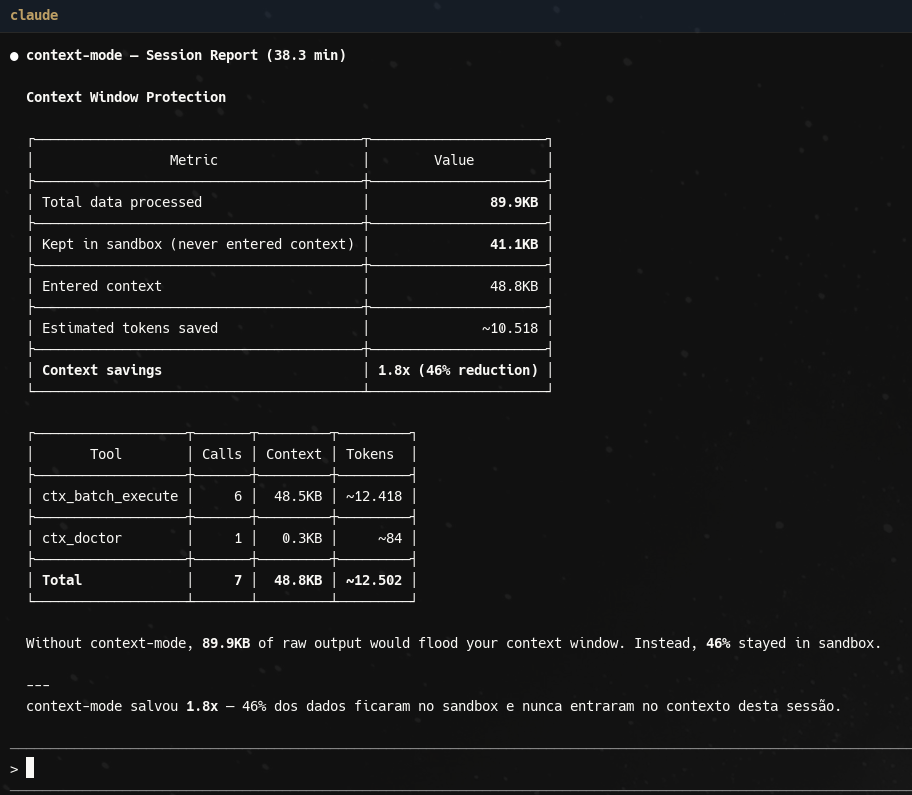
Nas últimas semanas, utilizei o Claud Code e Gemini CLI com Context-Mode a uma série de testes em ambiente real. Os números extraídos do “Session Report” não são apenas estatísticas; eles contam uma história de eficiência operacional e ganho de escala.
Em uma sessão típica de 38.3 minutos, os dados revelam um “performance audit” impressionante:
- Dados totais processados: 89.9 KB.
- Dados mantidos no sandbox (fora do contexto): 41.1 KB.
- Economia de contexto: 1.8x de ganho de eficiência (46% de redução de carga).
- Tokens preservados: Aproximadamente 10.518 tokens que nunca foram cobrados da janela de processamento.
O segredo dessa economia reside no uso de ferramentas especializadas. Durante a sessão, o sistema realizou 6 chamadas ao ctx_batch_execute, que lidou com 48.5 KB de dados e cerca de 12.418 tokens de forma externa, além de uma chamada ao ctx_doctor para diagnósticos pontuais. Na prática, isso significa que você recebe quase o dobro da janela de contexto efetiva sem pagar a “taxa de tokens” ou sofrer com o aumento de latência comum em contextos saturados.
Estudando o repositório do projeto identifiquei 4 pilares que ajudam a compreender como o plugin funciona tão bem
Pilar 1: A “Dieta Digital” e o Isolamento de Subprocessos
A estratégia para evitar o inchaço da memória é baseada em um mecanismo de isolamento técnico. Em vez de injetar arquivos de log massivos diretamente no prompt, o Context-Mode faz o spawn de um subprocesso isolado que processa a informação localmente.
“Um simples acesso a uma página de documentação ou log de erro pode consumir entre 45 KB e 60 KB de contexto instantaneamente, esgotando a capacidade de raciocínio do modelo.”
Para combater esse desperdício, o sistema utiliza filtragem baseada em intenção e Smart Snippets. Em testes de carga, observamos uma redução drástica: uma carga de trabalho de 315 KB foi reduzida para apenas 5,4 KB — uma economia de 98%. Se a saída de uma ferramenta excede 5 KB, o sistema indexa o conteúdo internamente e entrega à IA apenas os trechos cirurgicamente relevantes para a resolução do problema.
Pilar 2: Continuidade e Gestão de Estado via SQLite
Modelos de linguagem são, por definição, stateless. O Context-Mode resolve essa natureza efêmera implementando uma camada de persistência local robusta via SQLite. O banco de dados reside no diretório home do usuário (~/home), garantindo que o histórico de edições, comandos Git e decisões de design sejam preservados localmente durante a sessão.
A peça central dessa continuidade é o Guia de Sessão, que gerencia snapshots de estado com um orçamento rígido de apenas 2 KB. Quando a compactação se torna necessária, o sistema reconstrói o contexto em um formato de “checklist” estruturado. A IA recebe:
- Status de tarefas atualizado (ex:
[x]concluído,[ ]pendente). - Mapeamento de arquivos modificados na sessão.
- Log de erros não resolvidos e pendências técnicas.
Pilar 3: Privacidade Local e Segurança de Runtime
Como especialistas em DevRel, sabemos que a segurança do código proprietário é inegociável. No Context-Mode, a privacidade é uma escolha arquitetural: o processamento é 100% local, sem telemetria ou envio de dados para a nuvem.
O ambiente de execução (runtime) é versátil e focado em performance:
- Sandbox Multi-linguagem: Suporte nativo para 11 linguagens (Python, Go, Rust, Elixir, etc.).
- Otimização via Bun: Execuções de JavaScript e TypeScript são entre 3 a 5 vezes mais rápidas.
- Camada de Proteção Ativa: O sistema intercepta e bloqueia automaticamente comandos destrutivos sugeridos pela IA, como o famigerado
sudo rm -rf.
6. Pilar 4: O “Cérebro” de Busca Híbrida
Para garantir que a IA localize informações em milissegundos, o sistema utiliza um motor de busca sofisticado integrado ao SQLite FTS5.
| Técnica | Descrição Técnica e Aplicação Prática |
| FTS5 + BM25 | Algoritmo de ranking de relevância para classificar a importância de cada documento. |
| RRF (Reciprocal Rank Fusion) | Fusão de busca por radicais (Porter stemming) e correspondência por Trigramas. |
| Correção de Typos | Utiliza a Distância de Levenshtein para entender que “kuberntes” refere-se a “kubernetes”. |
| Reranking de Proximidade | Prioriza trechos onde os termos da busca aparecem fisicamente próximos no código. |
| Smart Extractions | Localiza janelas de máxima relevância e extrai snippets, evitando truncamentos arbitrários. |
Conclusão
A virtualização de contexto oferecido pelo context-mode transforma a IA de uma ferramenta reativa de “bate-papo” em um verdadeiro parceiro de engenharia de longo prazo. Ao gerenciar o estado de forma externa e eficiente, as barreiras físicas das janelas de contexto deixam de ser um limitador para a criatividade e produtividade do desenvolvedor.
Links úteis
Repositório do Context-Mode: https://github.com/mksglu/context-mode